alibaba/EasyTransfer

EasyTransfer is designed to make the development of transfer learning in NLP applications easier.
| repo name | alibaba/EasyTransfer |
| repo link | https://github.com/alibaba/EasyTransfer |
| homepage | https://www.yuque.com/easytransfer/cn/ |
| language | Python |
| size (curr.) | 1514 kB |
| stars (curr.) | 475 |
| created | 2020-09-02 |
| license | Apache License 2.0 |
The literature has witnessed the success of applying deep Transfer Learning (TL) for many real-world NLP applications, yet it is not easy to build an easy-to-use TL toolkit to achieve such a goal. To bridge this gap, EasyTransfer is designed to facilitate users leveraging deep TL for NLP applications at ease. It was developed in Alibaba in early 2017, and has been used in the major BUs in Alibaba group and achieved very good results in 20+ business scenarios. It supports the mainstream pre-trained ModelZoo, including pre-trained language models (PLMs) and multi-modal models on the PAI platform, integrates the SOTA models for the mainstream NLP applications in AppZoo, and supports knowledge distillation for PLMs. EasyTransfer is very convenient for users to quickly start model training, evaluation, offline prediction, and online deployment. It also provides rich APIs to make the development of NLP and transfer learning easier.
Main Features
- Language model pre-training tool: it supports a comprehensive pre-training tool for users to pre-train language models such as T5 and BERT. Based on the tool, the user can easily train a model to achieve great results in the benchmark leaderboards such as CLUE, GLUE, and SuperGLUE;
- ModelZoo with rich and high-quality pre-trained models: supports the Continual Pre-training and Fine-tuning of mainstream LM models such as BERT, ALBERT, RoBERTa, T5, etc. It also supports a multi-modal model FashionBERT developed using the fashion domain data in Alibaba;
- AppZoo with rich and easy-to-use applications: supports mainstream NLP applications and those models developed inside of Alibaba, e.g.: HCNN for text matching, and BERT-HAE for MRC.
- Automatic knowledge distillation: supports task-adaptive knowledge distillation to distill knowledge from a teacher model to a small task-specific student model. The resulting method is AdaBERT, which uses a neural architecture search method to find a task-specific architecture to compress the original BERT model. The compressed models are 12.7x to 29.3x faster than BERT in inference time and 11.5x to 17.0x smaller in terms of parameter size and with comparable performance.
- Easy-to-use and high-performance distributed strategy: based on the in-house PAI features, it provides easy-to-use and high-performance distributed strategy for multiple CPU/GPU training.
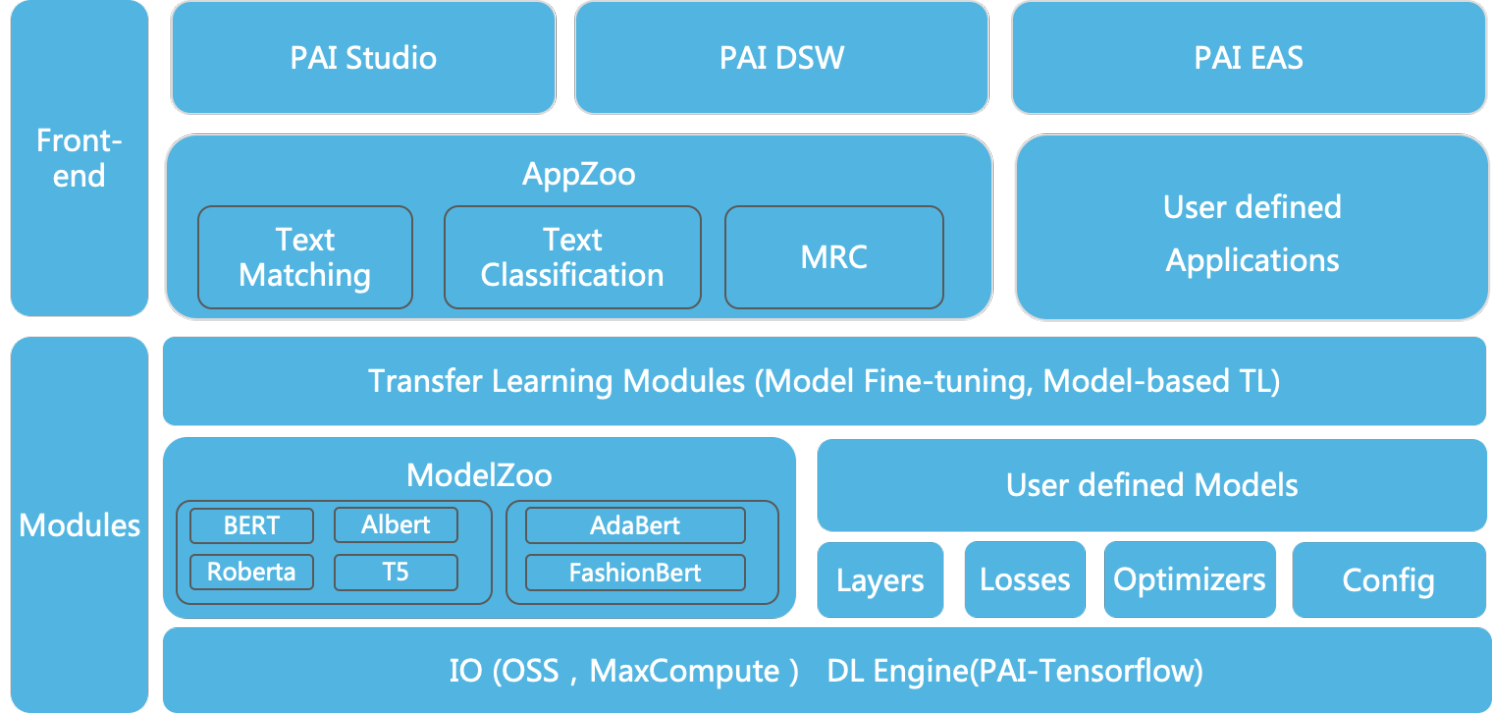
Architecture
Installation
You can either install from pip
$ pip install easytransfer
or setup from the source:
$ git clone https://github.com/alibaba/EasyTransfer.git
$ cd EasyTransfer
$ python setup.py install
This repo is tested on Python3.6/2.7, tensorflow 1.12.3
Quick Start
Now let’s show how to use just 30 lines of code to build a text classification model based on BERT.
from easytransfer import base_model, layers, model_zoo, preprocessors
from easytransfer.datasets import CSVReader, CSVWriter
from easytransfer.losses import softmax_cross_entropy
from easytransfer.evaluators import classification_eval_metrics
class TextClassification(base_model):
def __init__(self, **kwargs):
super(TextClassification, self).__init__(**kwargs)
self.pretrained_model_name = "google-bert-base-en"
self.num_labels = 2
def build_logits(self, features, mode=None):
preprocessor = preprocessors.get_preprocessor(self.pretrained_model_name)
model = model_zoo.get_pretrained_model(self.pretrained_model_name)
dense = layers.Dense(self.num_labels)
input_ids, input_mask, segment_ids, label_ids = preprocessor(features)
_, pooled_output = model([input_ids, input_mask, segment_ids], mode=mode)
return dense(pooled_output), label_ids
def build_loss(self, logits, labels):
return softmax_cross_entropy(labels, self.num_labels, logits)
def build_eval_metrics(self, logits, labels):
return classification_eval_metrics(logits, labels, self.num_labels)
app = TextClassification()
train_reader = CSVReader(input_glob=app.train_input_fp, is_training=True, batch_size=app.train_batch_size)
eval_reader = CSVReader(input_glob=app.eval_input_fp, is_training=False, batch_size=app.eval_batch_size)
app.run_train_and_evaluate(train_reader=train_reader, eval_reader=eval_reader)
You can find more details or play with the code in our Jupyter/Notebook PAI-DSW.
You can also use AppZoo Command Line Tools to quickly train an App model. Take text classification on SST-2 dataset as an example. First you can download the train.tsv, dev.tsv and test.tsv, then start training:
$ easy_transfer_app --mode train \
--inputTable=./train.tsv,./dev.tsv \
--inputSchema=content:str:1,label:str:1 \
--firstSequence=content \
--sequenceLength=128 \
--labelName=label \
--labelEnumerateValues=0,1 \
--checkpointDir=./sst2_models/\
--numEpochs=3 \
--batchSize=32 \
--optimizerType=adam \
--learningRate=2e-5 \
--modelName=text_classify_bert \
--advancedParameters='pretrain_model_name_or_path=google-bert-base-en'
And then predict:
$ easy_transfer_app --mode predict \
--inputTable=./test.tsv \
--outputTable=./test.pred.tsv \
--inputSchema=id:str:1,content:str:1 \
--firstSequence=content \
--appendCols=content \
--outputSchema=predictions,probabilities,logits \
--checkpointPath=./sst2_models/
To learn more about the usage of AppZoo, please refer to our documentation.
Tutorials
- PAI-ModelZoo (20+ pretrained models)
- FashionBERT-cross-modality pretrained model
- Knowledge Distillation including vanilla KD, Probes KD, AdaBERT
- BERT Feature Extraction
- Text Matching including BERT, BERT Two Tower, DAM, HCNN
- Text Classification including BERT, TextCNN
- Machine Reading Comprehesion including BERT, BERT-HAE
- Sequence Labeling including BERT
- Meta Fine-tuning for Cross-domain Text Classification
CLUE Benchmark
| TNEWS | AFQMC | IFLYTEK | CMNLI | CSL | Average | |
|---|---|---|---|---|---|---|
| google-bert-base-zh | 0.6673 | 0.7375 | 0.5968 | 0.7981 | 0.7976 | 0.7194 |
| pai-bert-base-zh | 0.6694 | 0.7412 | 0.6114 | 0.7967 | 0.7993 | 0.7236 |
| hit-roberta-base-zh | 0.6734 | 0.7418 | 0.6052 | 0.8010 | 0.8010 | 0.7245 |
| hit-roberta-large-zh | 0.6742 | 0.7521 | 0.6052 | 0.8231 | 0.8100 | 0.7329 |
| google-albert-xxlarge-zh | 0.6253 | 0.6899 | 0.5017 | 0.7721 | 0.7106 | 0.6599 |
| pai-albert-xxlarge-zh | 0.6809 | 0.7525 | 0.6118 | 0.8284 | 0.8137 | 0.7375 |
You can find more benchmarks in https://www.yuque.com/easytransfer/cn/rkm4p7
Here is the CLUE quick start notebook
Links
Tutorials:https://www.yuque.com/easytransfer/itfpm9/qtzvuc
ModelZoo:https://www.yuque.com/easytransfer/itfpm9/oszcof
AppZoo:https://www.yuque.com/easytransfer/itfpm9/ky6hky
API docs:http://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/eztransfer_docs/html/index.html
Contact Us
Scan the following QR codes to join Dingtalk discussion group. The group discussions are most in Chinese, but English is also welcomed.
Also we can scan the following QR code to join wechat discussion group.
Citation
@article{easytransfer,
author = {Minghui Qiu and
Peng Li and
Hanjie Pan and
Chengyu Wang and
Cen Chen and
Yaliang Li and
Dehong Gao and
Jun Huang and
Yong Li and
Jun Yang and
Deng Cai and
Wei Lin},
title = {EasyTransfer - A Simple and Scalable Deep Transfer Learning Platform for NLP Applications
},
journal = {arXiv:2011.09463},
url = {https://arxiv.org/abs/2011.09463},
year = {2020}
}






