ShangtongZhang/reinforcement-learning-an-introduction

Python Implementation of Reinforcement Learning: An Introduction
| repo name | ShangtongZhang/reinforcement-learning-an-introduction |
| repo link | https://github.com/ShangtongZhang/reinforcement-learning-an-introduction |
| homepage | |
| language | Python |
| size (curr.) | 5442 kB |
| stars (curr.) | 8239 |
| created | 2016-09-13 |
| license | MIT License |
Reinforcement Learning: An Introduction

Python replication for Sutton & Barto’s book Reinforcement Learning: An Introduction (2nd Edition)
If you have any confusion about the code or want to report a bug, please open an issue instead of emailing me directly. And unfortunately I do not have exercise answers for the book.
Contents
Chapter 1
- Tic-Tac-Toe
Chapter 2
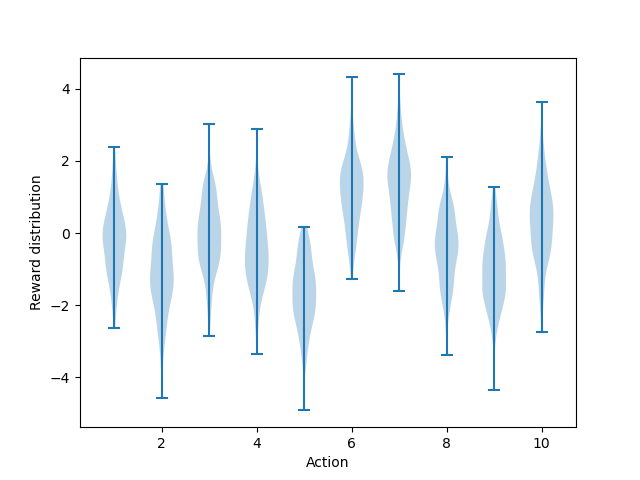
- Figure 2.1: An exemplary bandit problem from the 10-armed testbed
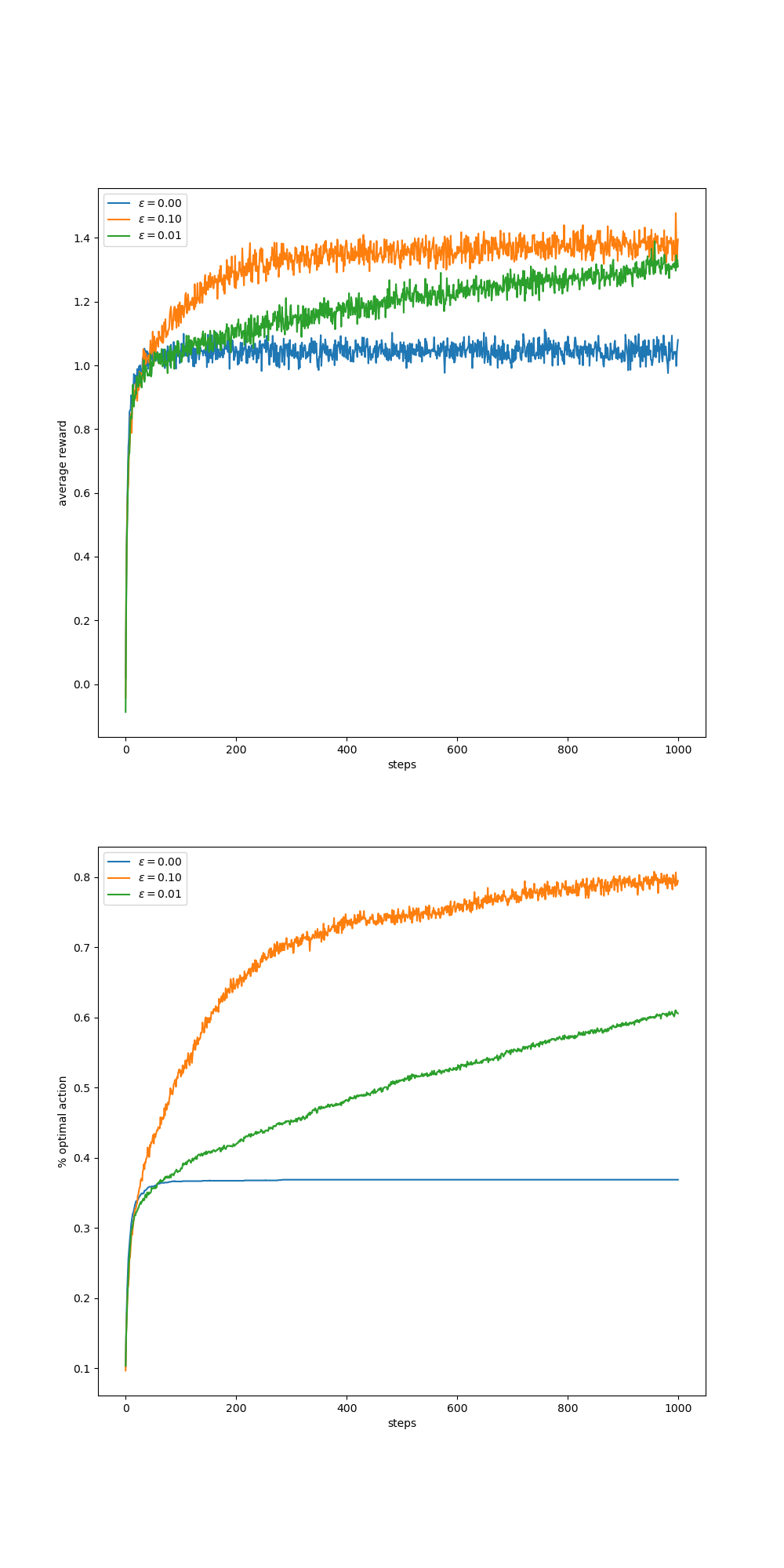
- Figure 2.2: Average performance of epsilon-greedy action-value methods on the 10-armed testbed
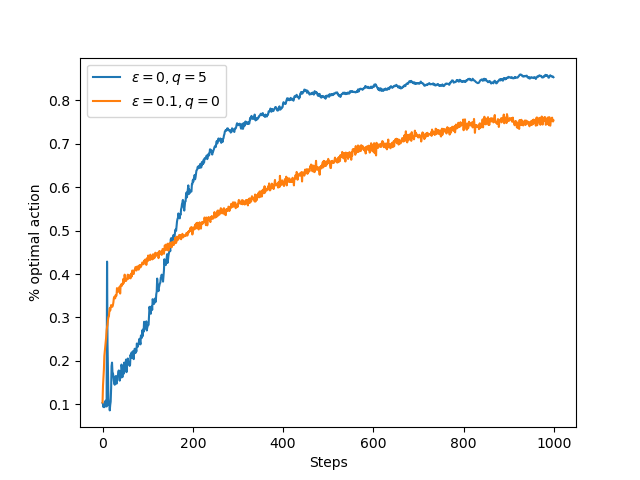
- Figure 2.3: Optimistic initial action-value estimates
- Figure 2.4: Average performance of UCB action selection on the 10-armed testbed
- Figure 2.5: Average performance of the gradient bandit algorithm
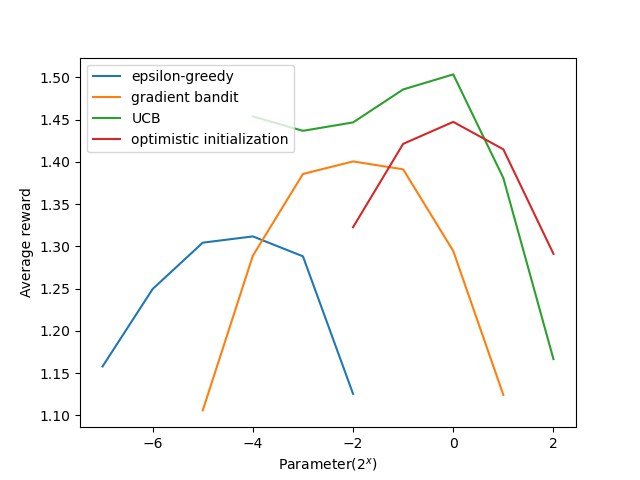
- Figure 2.6: A parameter study of the various bandit algorithms
Chapter 3
Chapter 4
- Figure 4.1: Convergence of iterative policy evaluation on a small gridworld
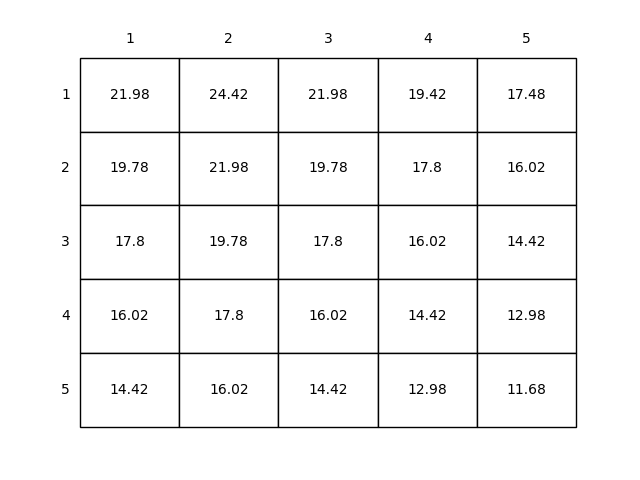
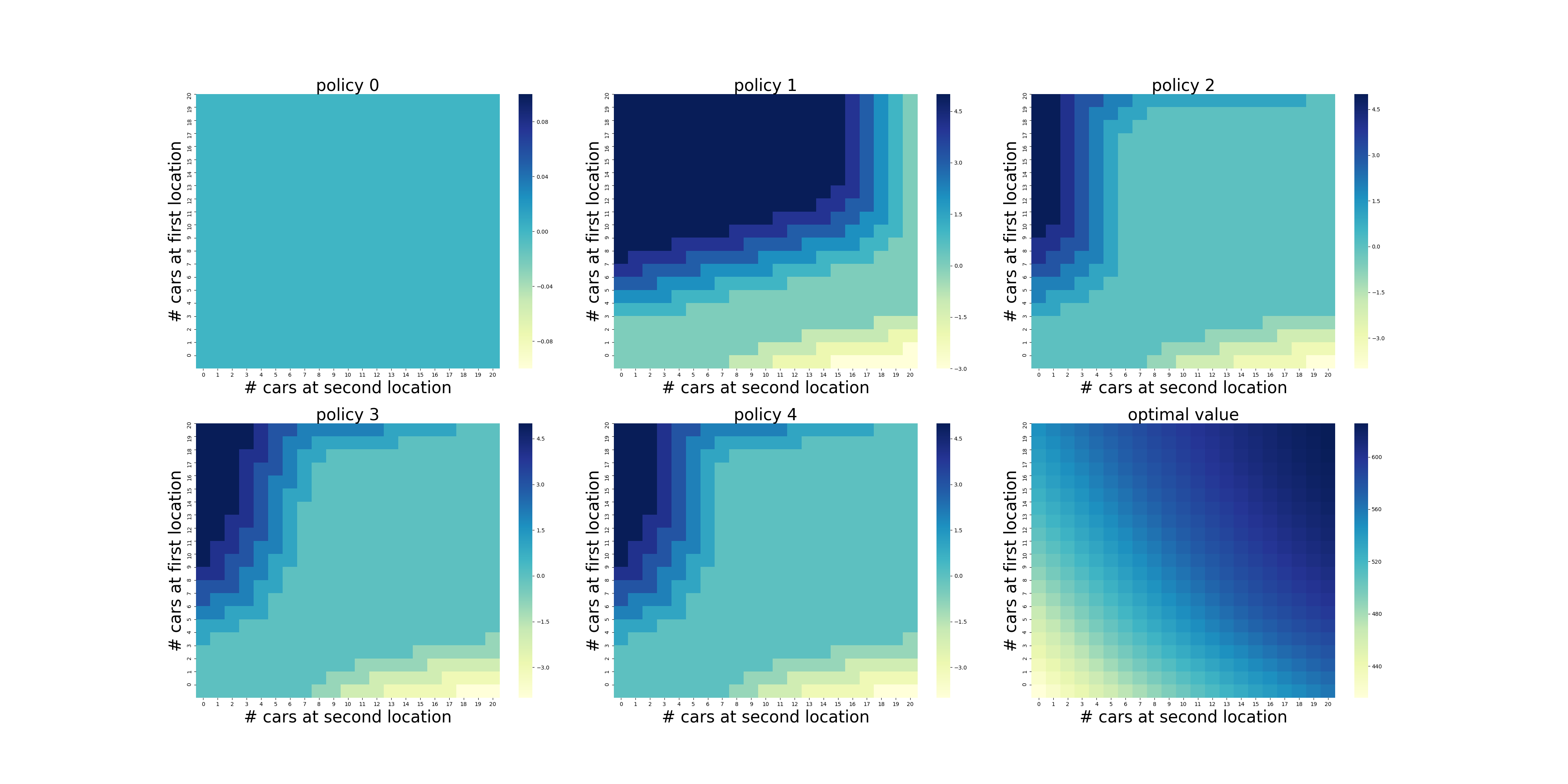
- Figure 4.2: Jack’s car rental problem
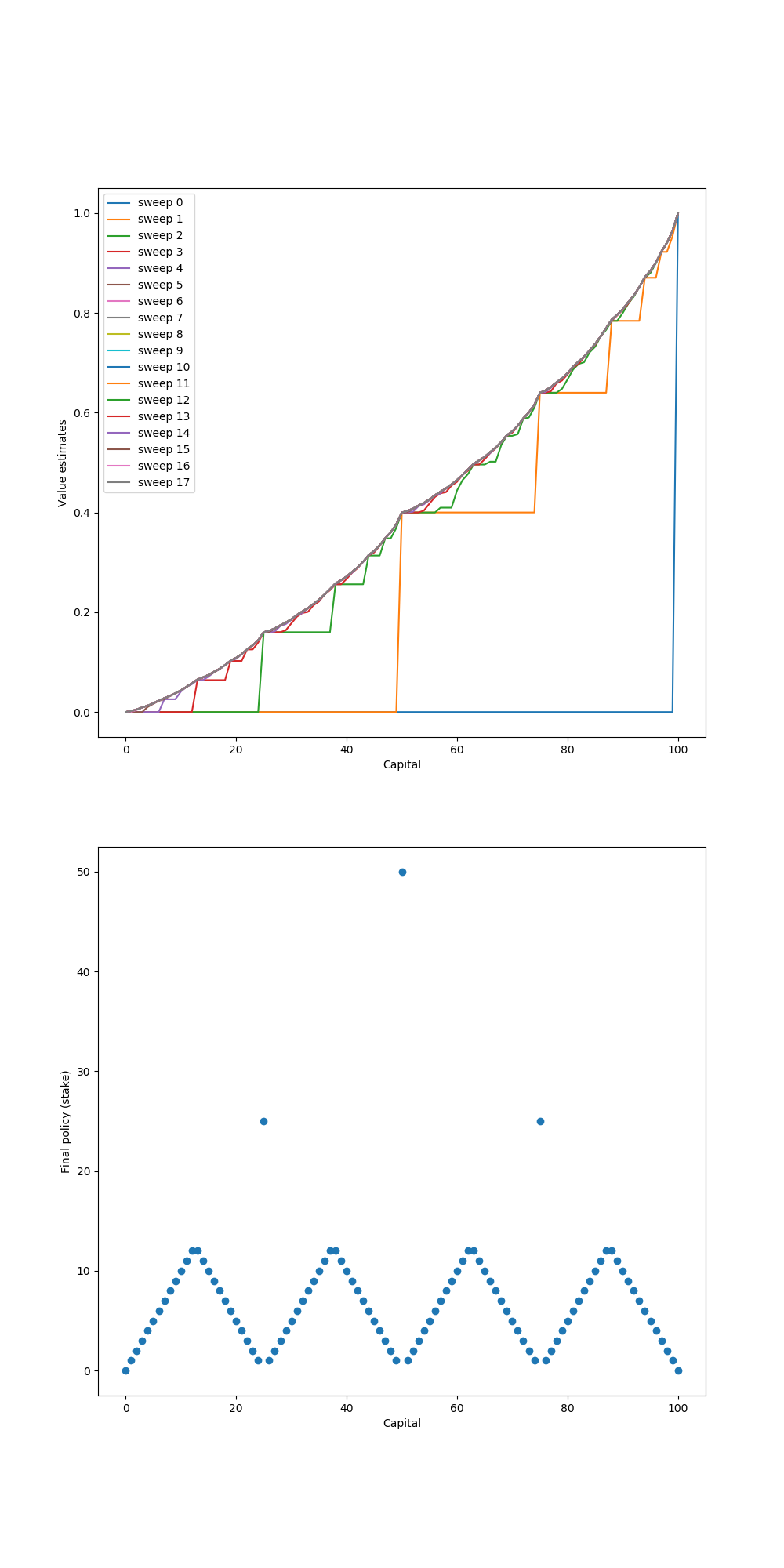
- Figure 4.3: The solution to the gambler’s problem
Chapter 5
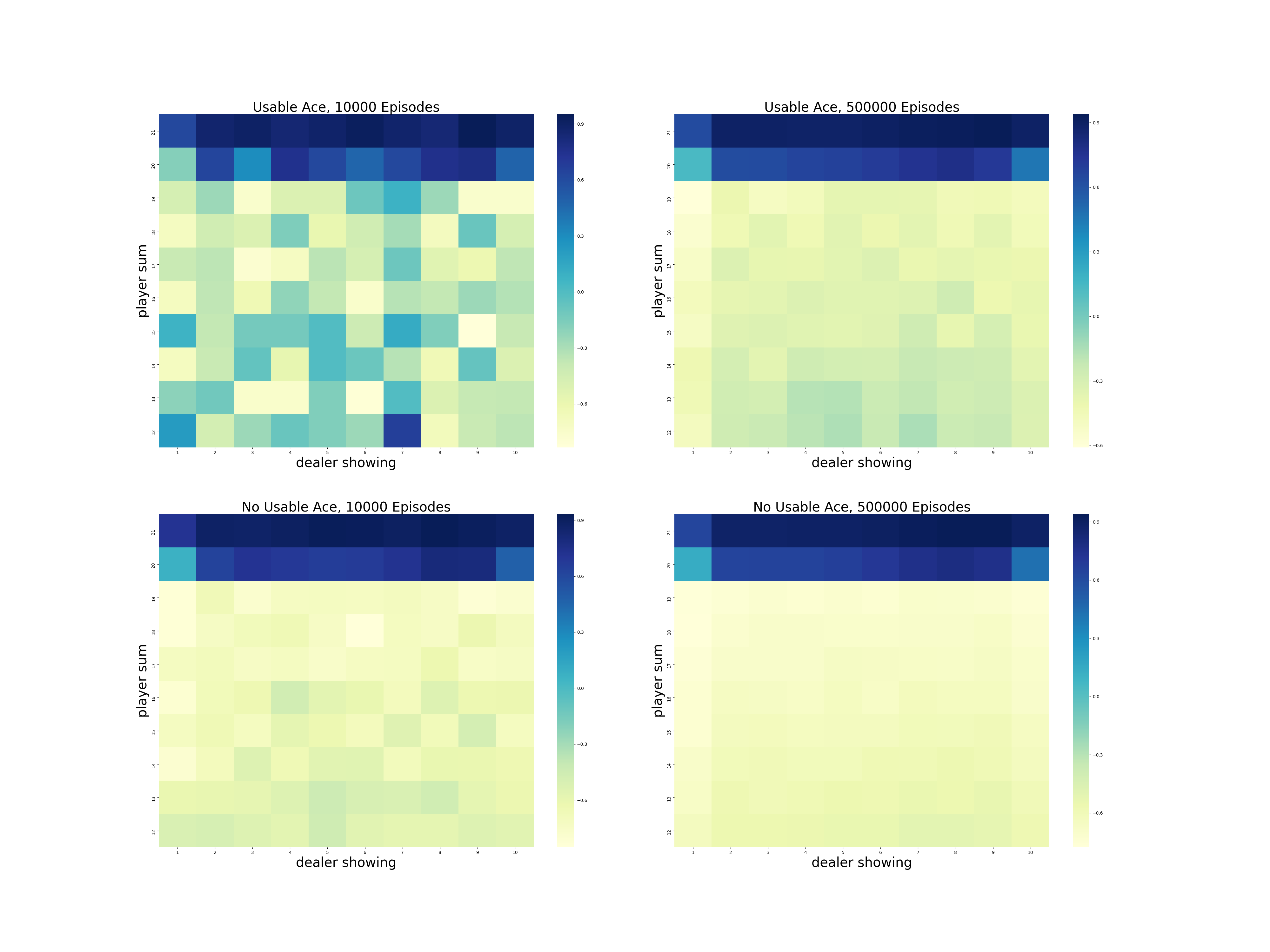
- Figure 5.1: Approximate state-value functions for the blackjack policy
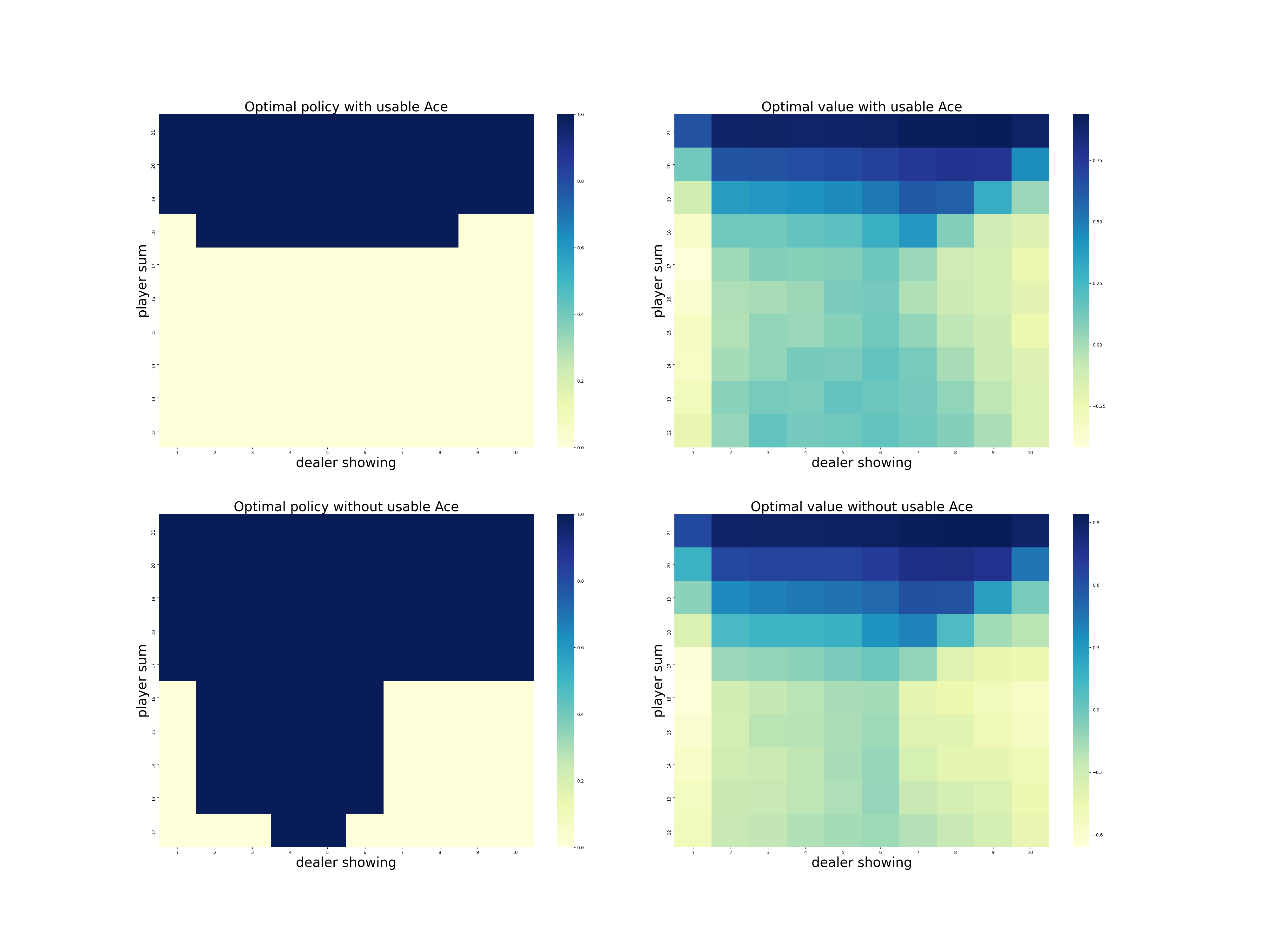
- Figure 5.2: The optimal policy and state-value function for blackjack found by Monte Carlo ES
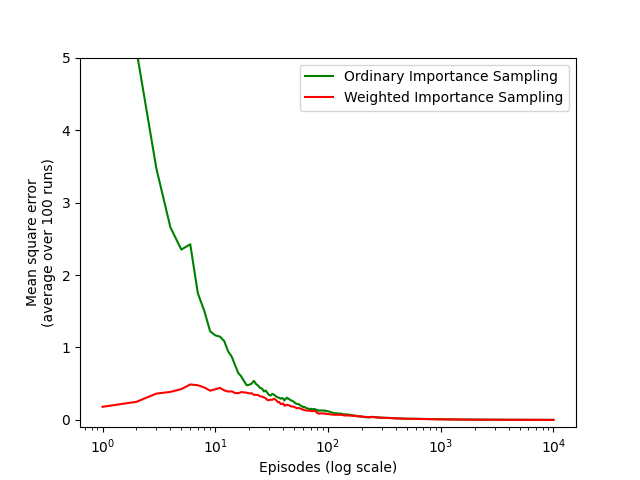
- Figure 5.3: Weighted importance sampling
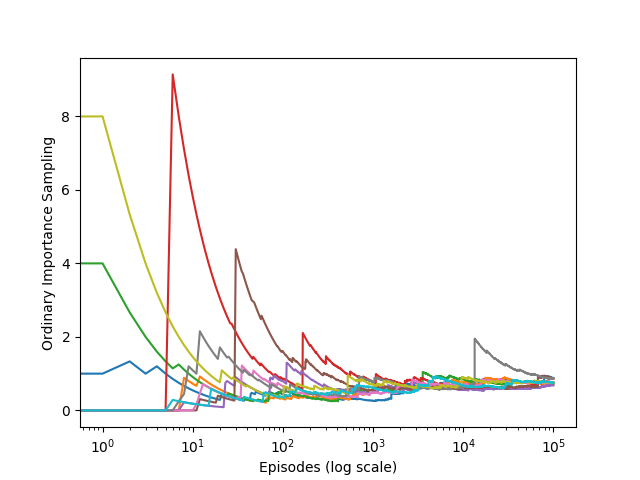
- Figure 5.4: Ordinary importance sampling with surprisingly unstable estimates
Chapter 6
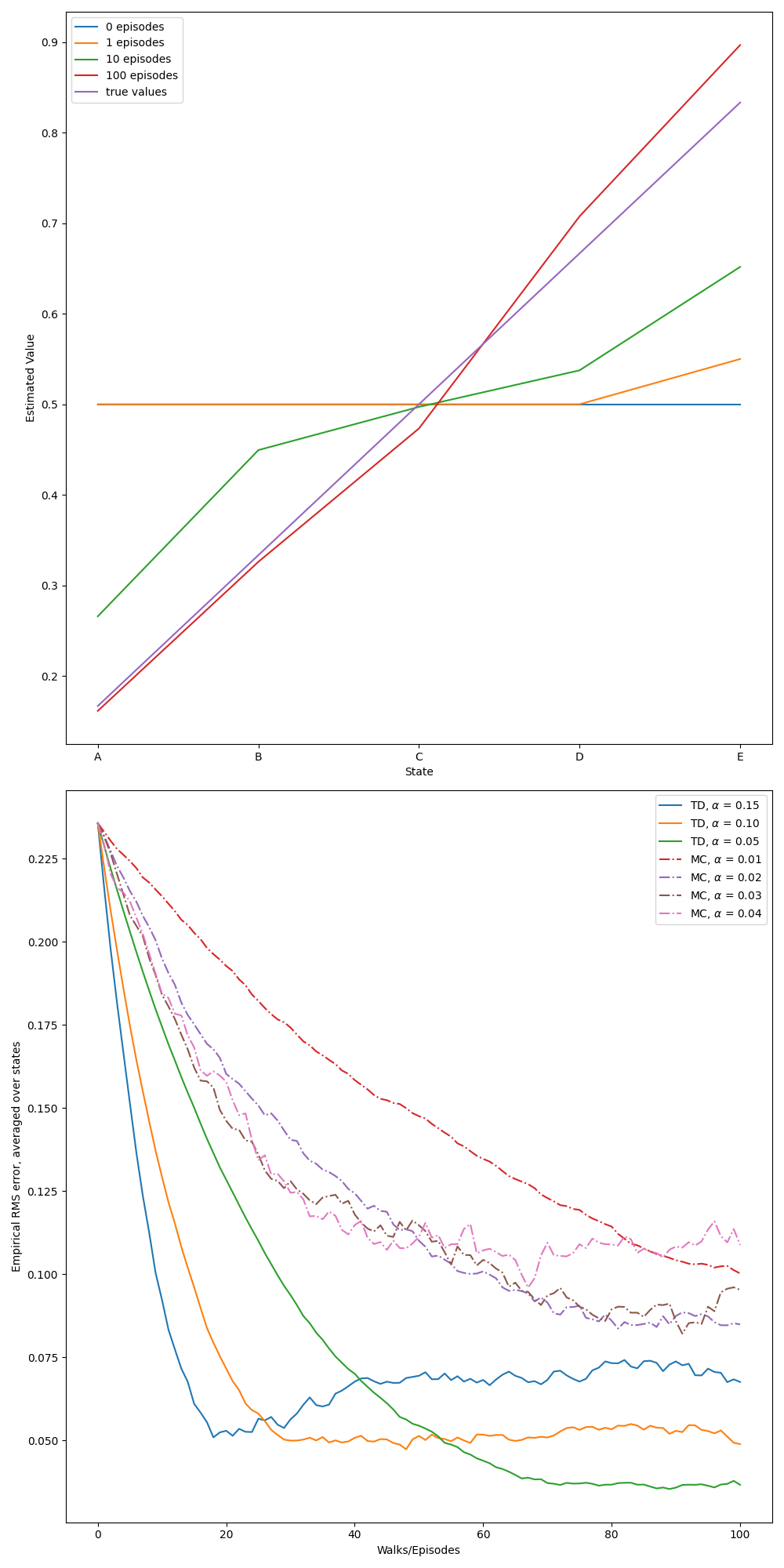
- Example 6.2: Random walk
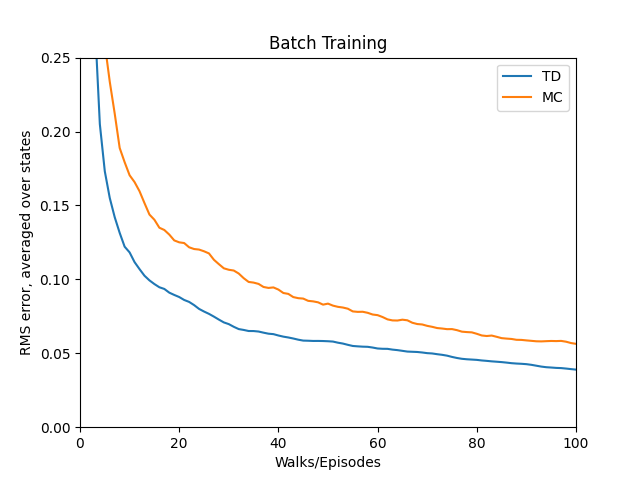
- Figure 6.2: Batch updating
- Figure 6.3: Sarsa applied to windy grid world
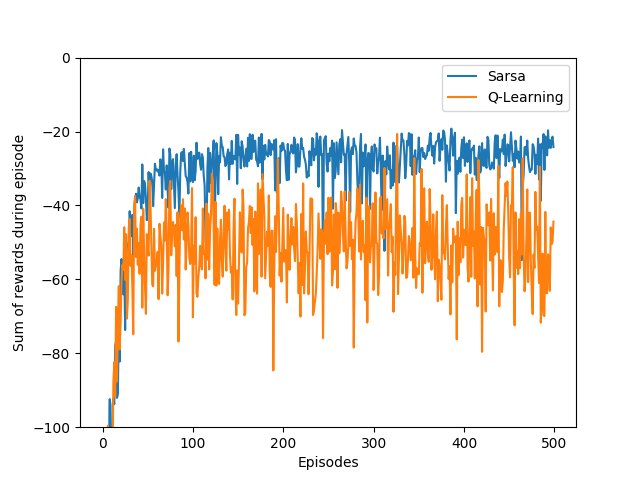
- Figure 6.4: The cliff-walking task
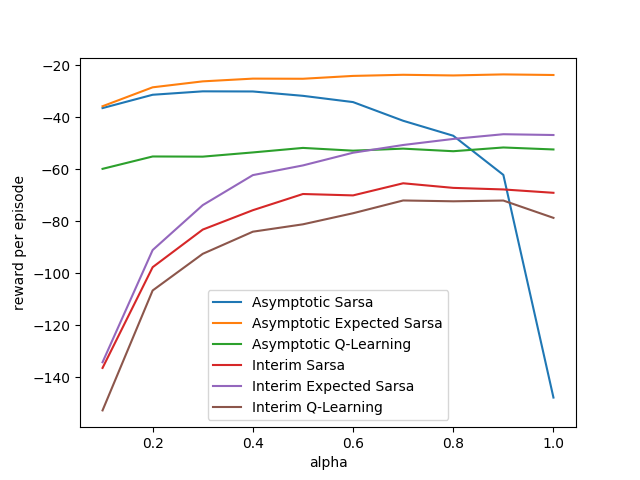
- Figure 6.6: Interim and asymptotic performance of TD control methods
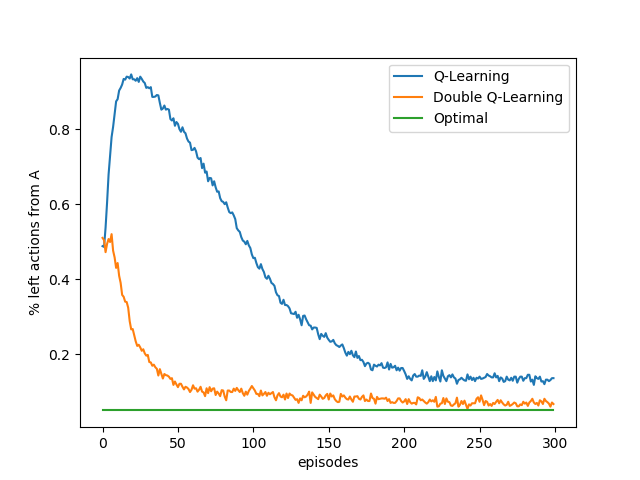
- Figure 6.7: Comparison of Q-learning and Double Q-learning
Chapter 7
Chapter 8
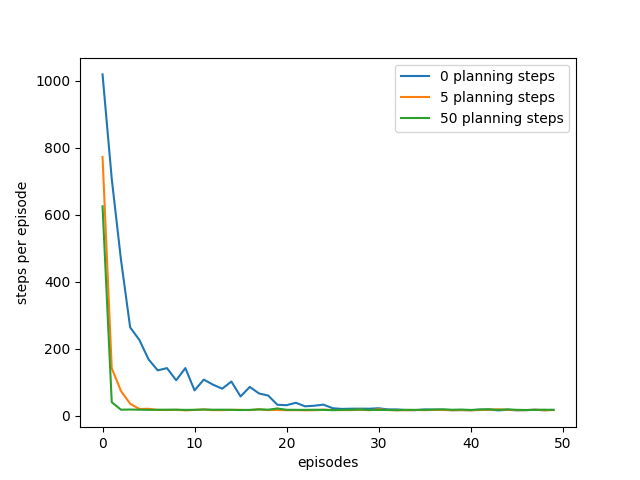
- Figure 8.2: Average learning curves for Dyna-Q agents varying in their number of planning steps
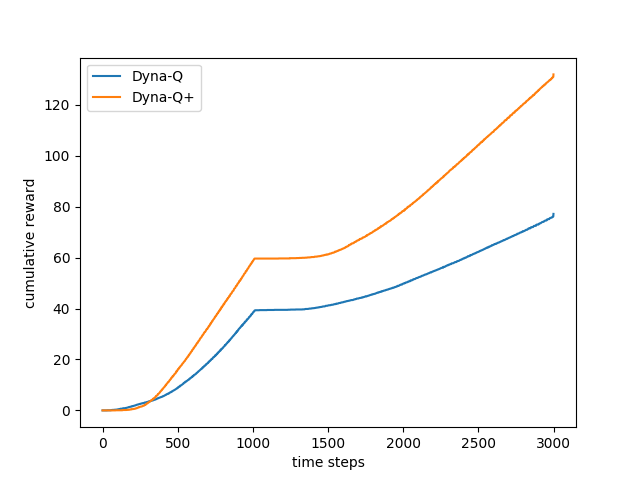
- Figure 8.4: Average performance of Dyna agents on a blocking task
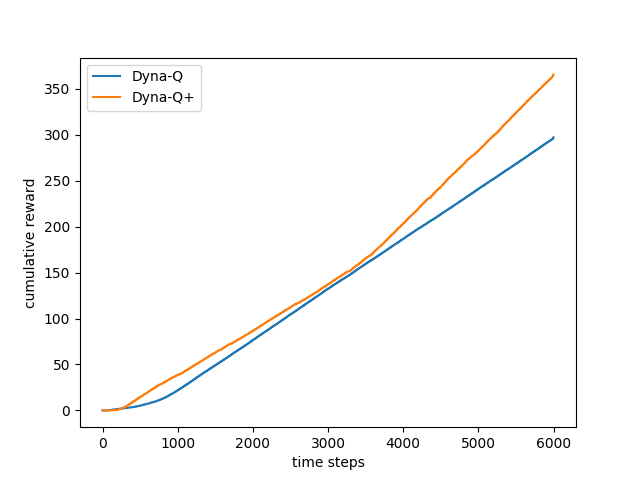
- Figure 8.5: Average performance of Dyna agents on a shortcut task
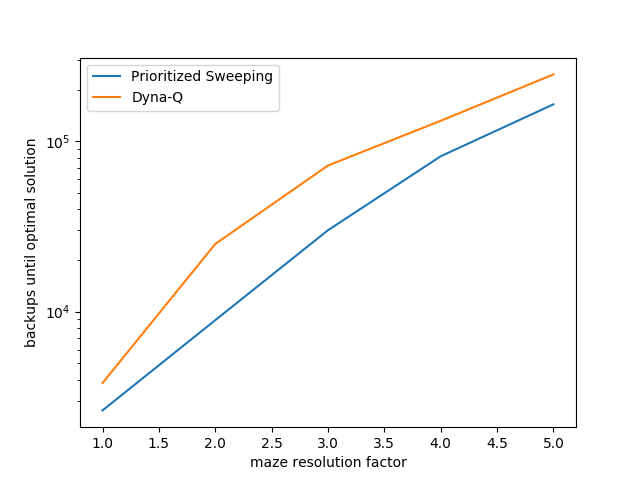
- Example 8.4: Prioritized sweeping significantly shortens learning time on the Dyna maze task
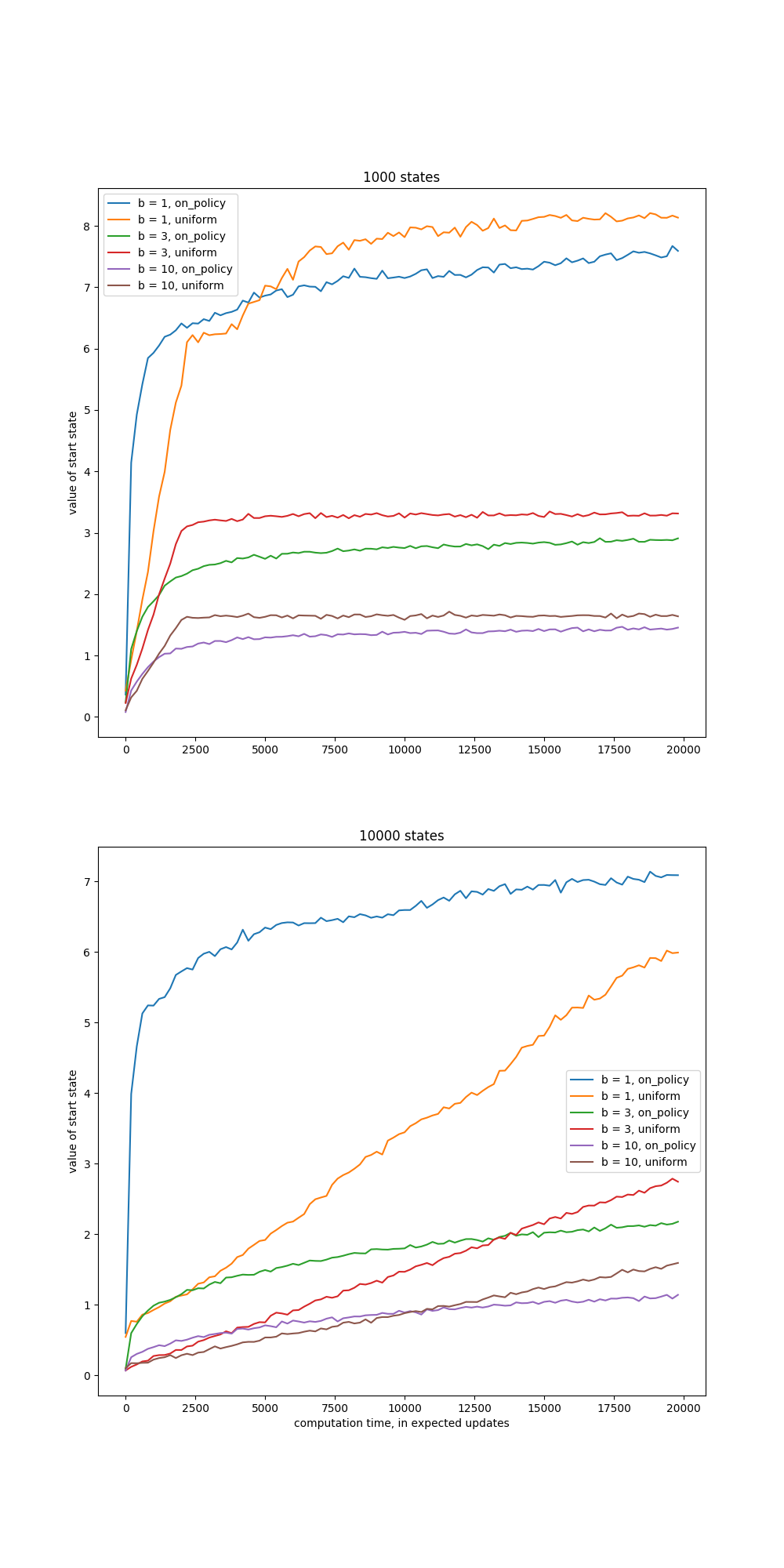
- Figure 8.7: Comparison of efficiency of expected and sample updates
- Figure 8.8: Relative efficiency of different update distributions
Chapter 9
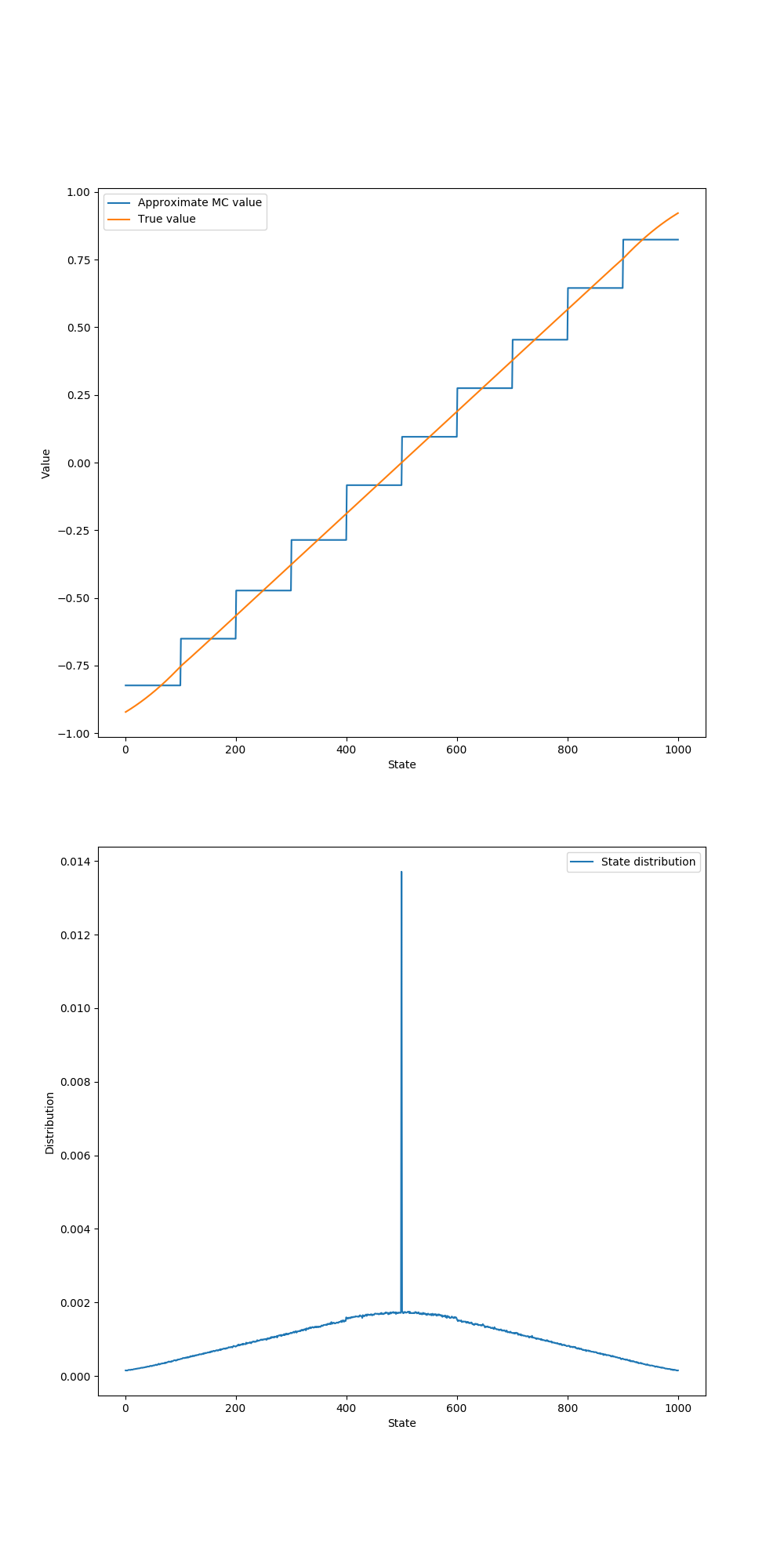
- Figure 9.1: Gradient Monte Carlo algorithm on the 1000-state random walk task
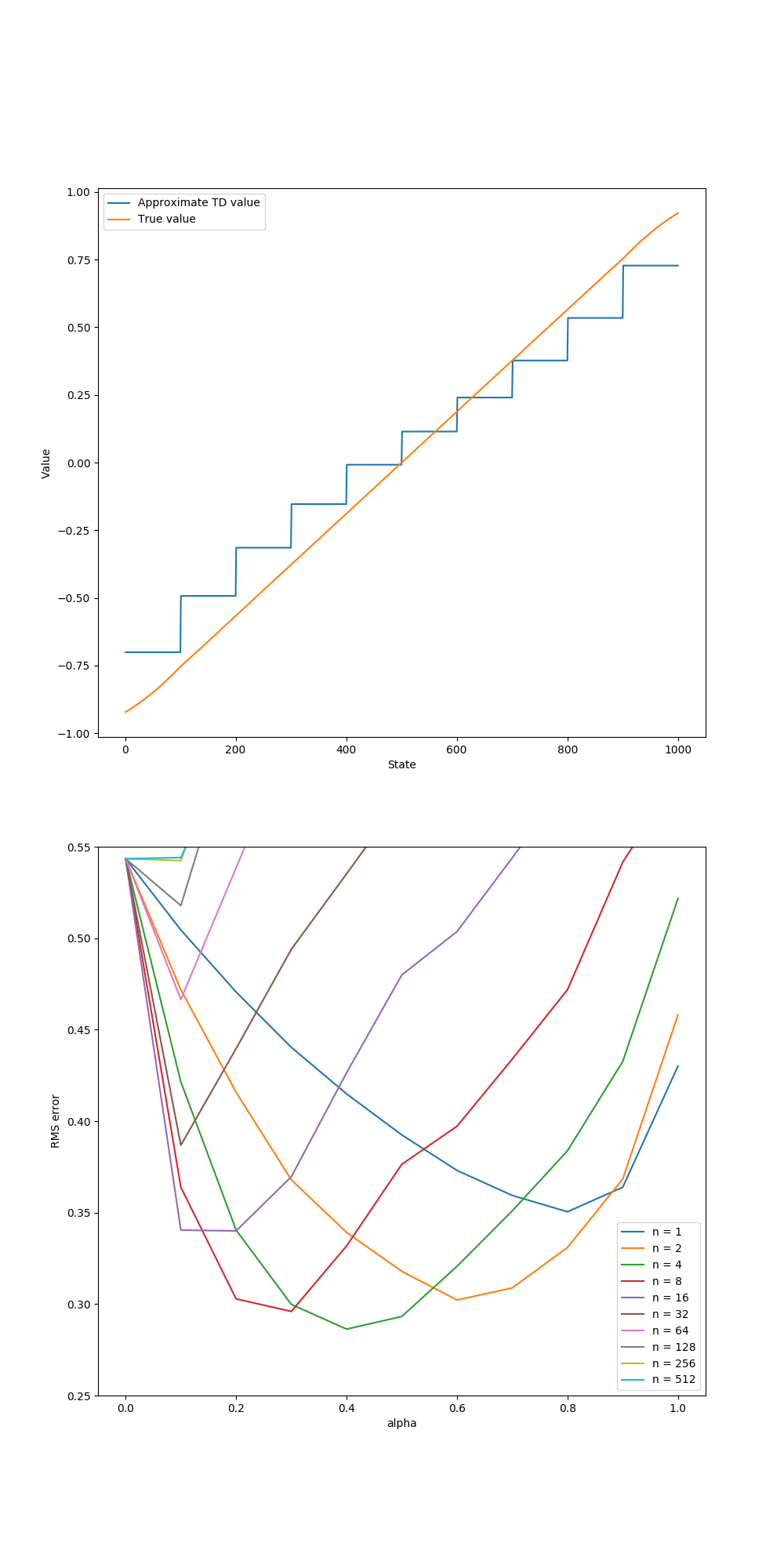
- Figure 9.2: Semi-gradient n-steps TD algorithm on the 1000-state random walk task
- Figure 9.5: Fourier basis vs polynomials on the 1000-state random walk task
- Figure 9.8: Example of feature width’s effect on initial generalization and asymptotic accuracy
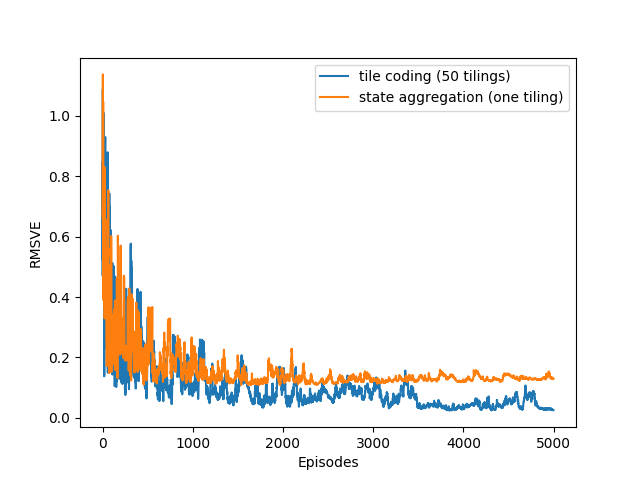
- Figure 9.10: Single tiling and multiple tilings on the 1000-state random walk task
Chapter 10
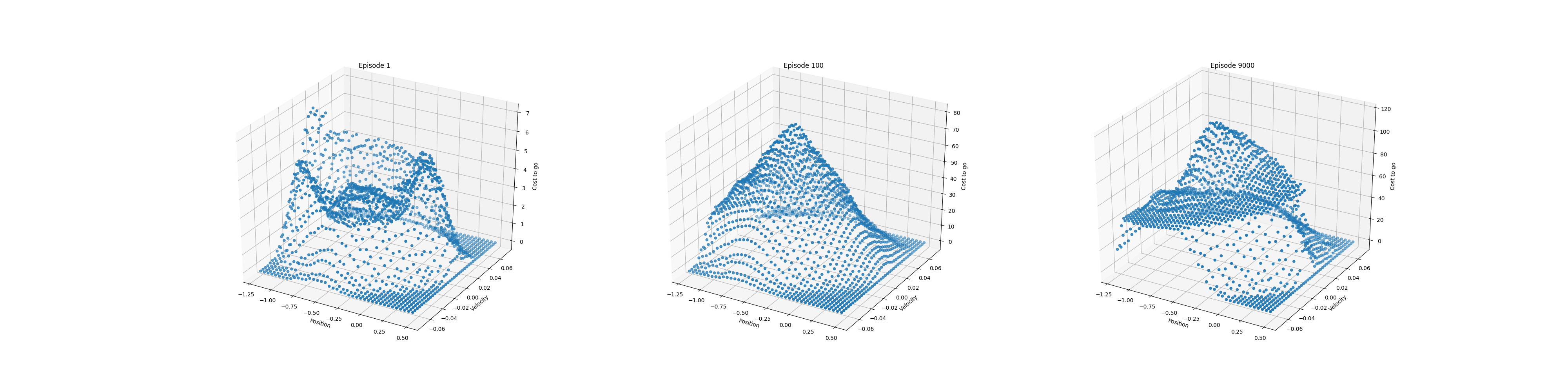
- Figure 10.1: The cost-to-go function for Mountain Car task in one run
- Figure 10.2: Learning curves for semi-gradient Sarsa on Mountain Car task
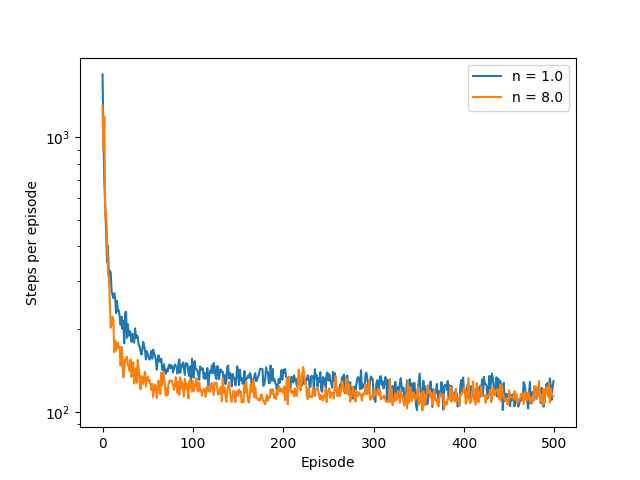
- Figure 10.3: One-step vs multi-step performance of semi-gradient Sarsa on the Mountain Car task
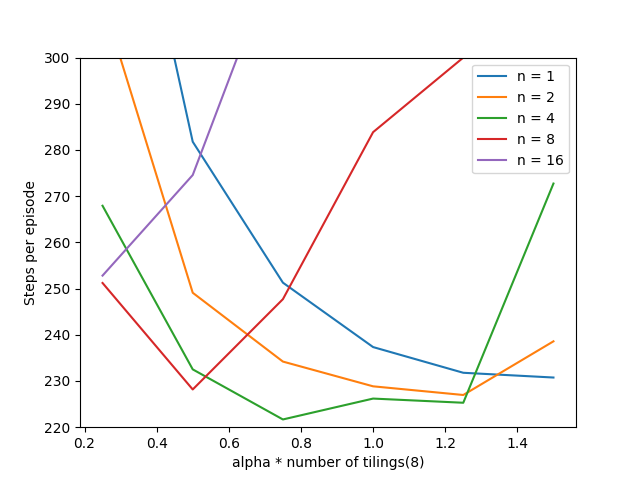
- Figure 10.4: Effect of the alpha and n on early performance of n-step semi-gradient Sarsa
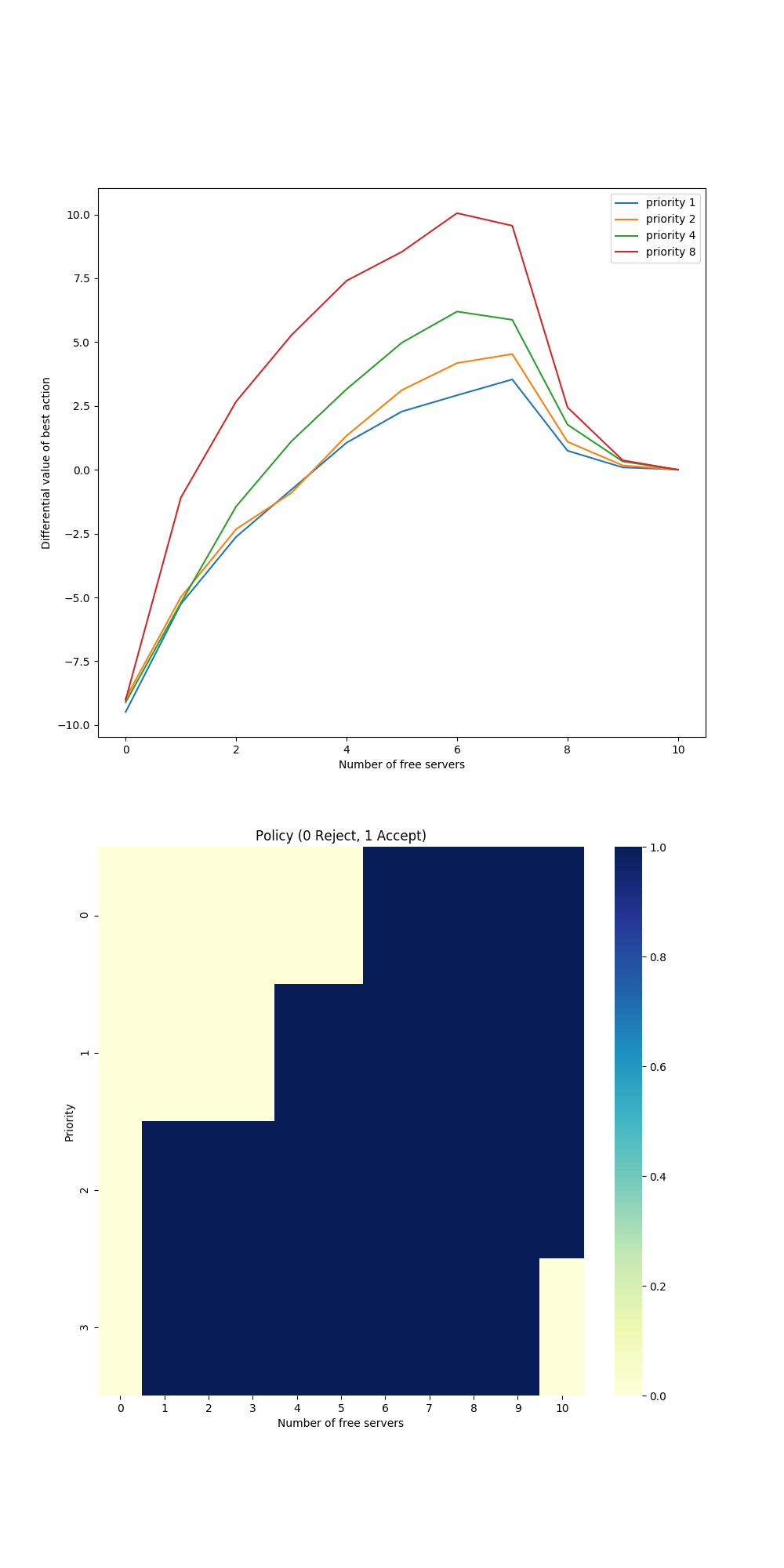
- Figure 10.5: Differential semi-gradient Sarsa on the access-control queuing task
Chapter 11
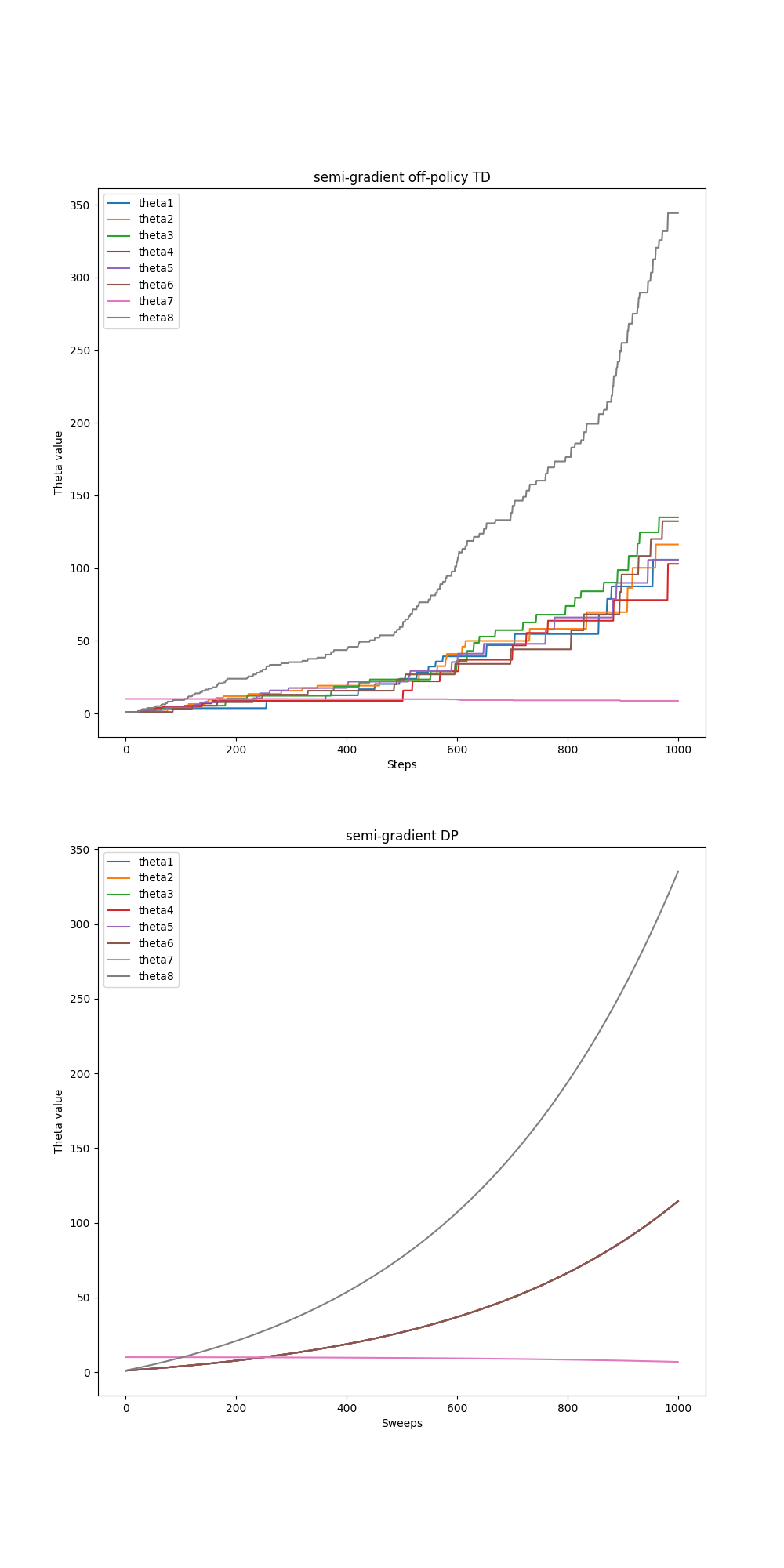
- Figure 11.2: Baird’s Counterexample
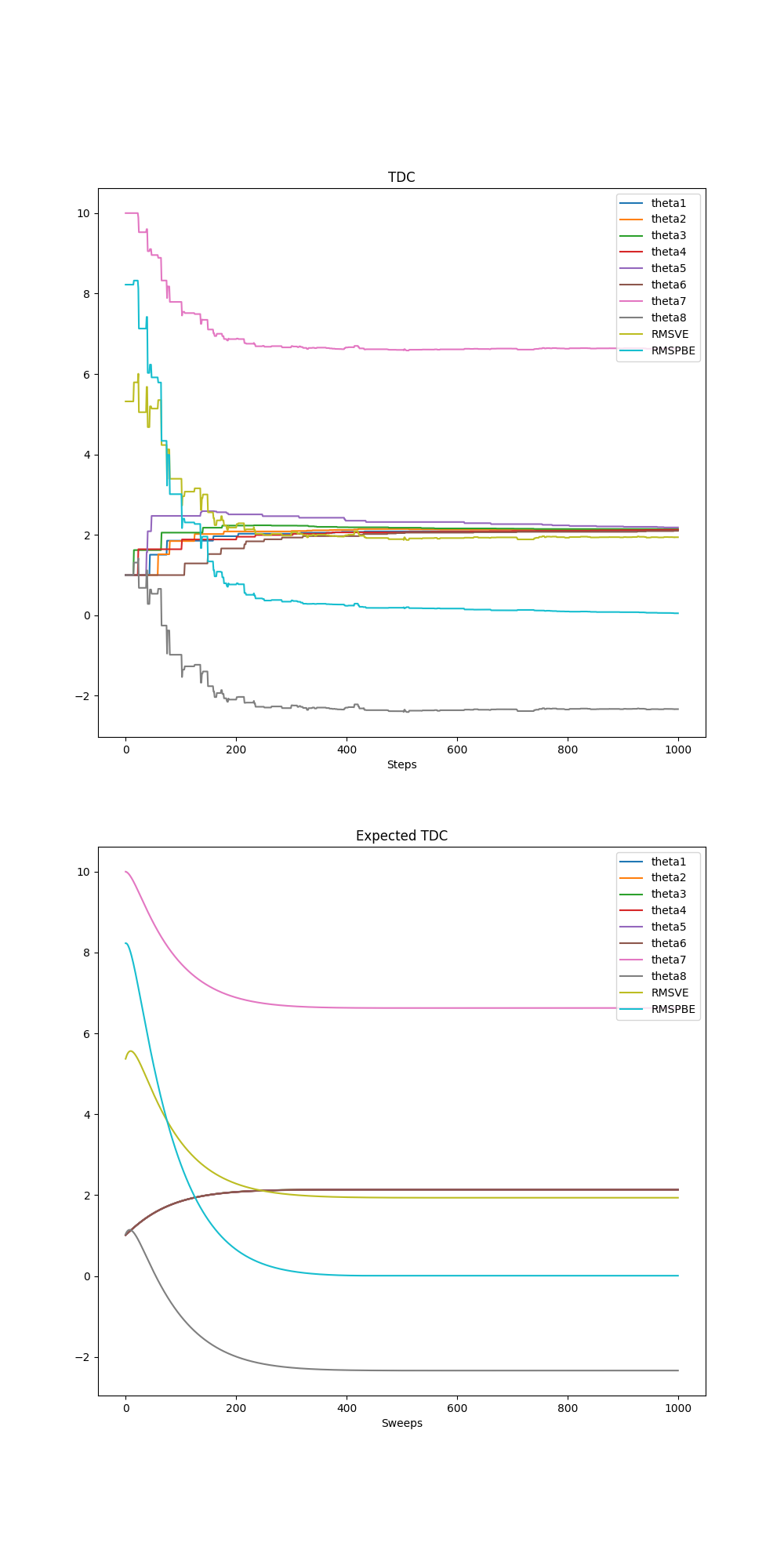
- Figure 11.6: The behavior of the TDC algorithm on Baird’s counterexample
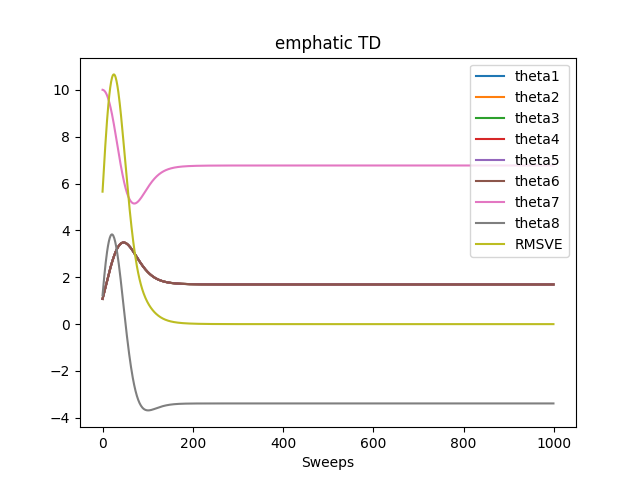
- Figure 11.7: The behavior of the ETD algorithm in expectation on Baird’s counterexample
Chapter 12
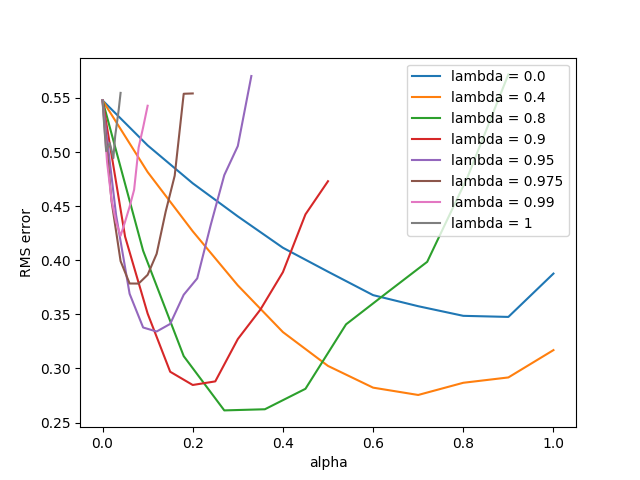
- Figure 12.3: Off-line λ-return algorithm on 19-state random walk
- Figure 12.6: TD(λ) algorithm on 19-state random walk
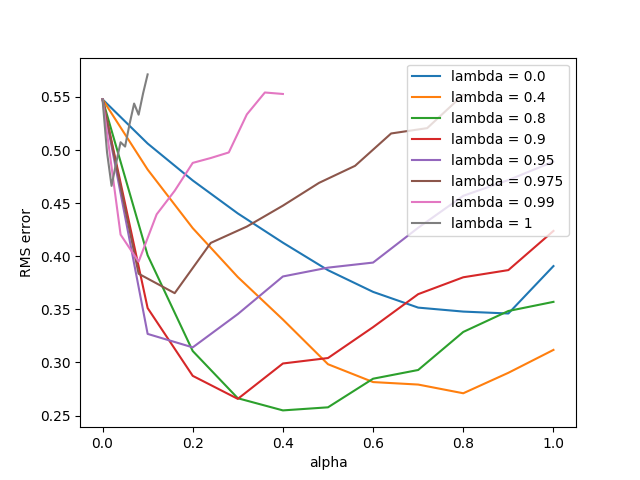
- Figure 12.8: True online TD(λ) algorithm on 19-state random walk
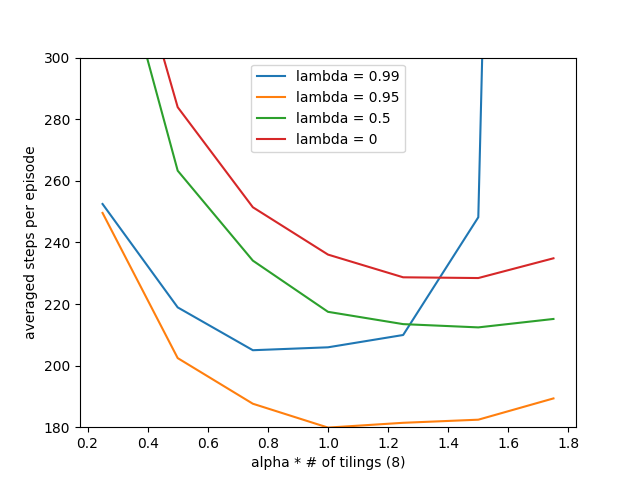
- Figure 12.10: Sarsa(λ) with replacing traces on Mountain Car
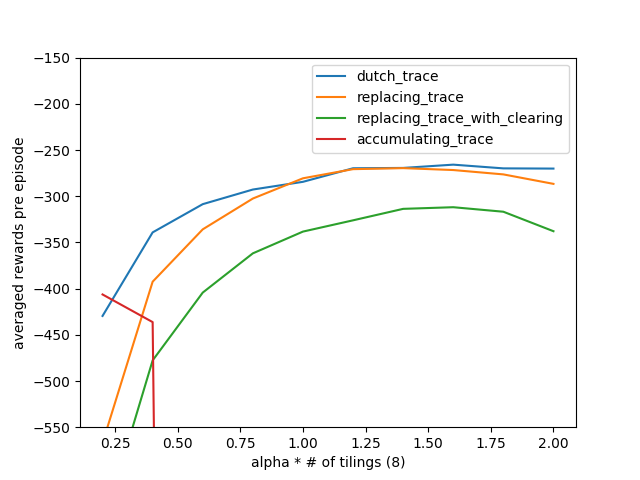
- Figure 12.11: Summary comparison of Sarsa(λ) algorithms on Mountain Car
Chapter 13
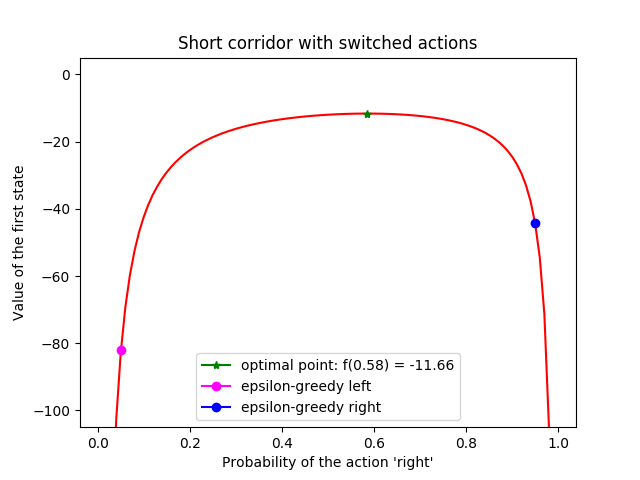
- Example 13.1: Short corridor with switched actions
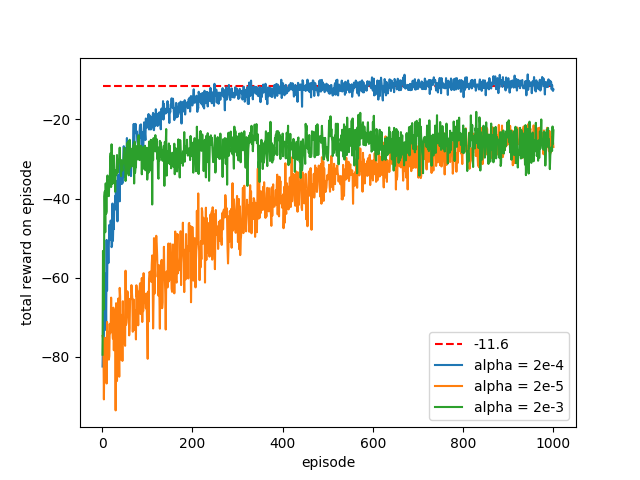
- Figure 13.1: REINFORCE on the short-corridor grid world
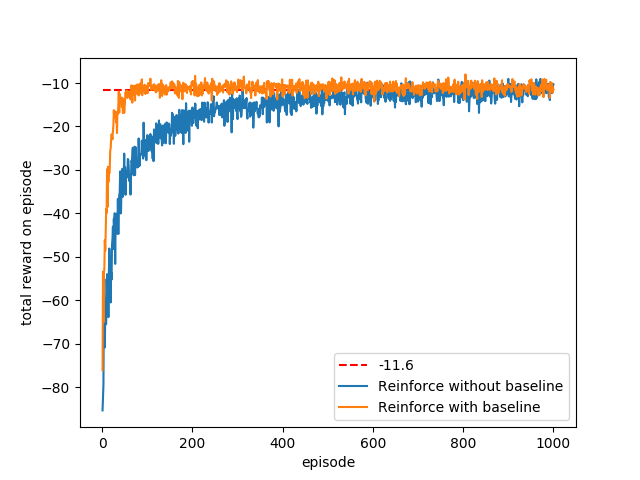
- Figure 13.2: REINFORCE with baseline on the short-corridor grid-world
Environment
Usage
All files are self-contained
python any_file_you_want.py
Contribution
If you want to contribute some missing examples or fix some bugs, feel free to open an issue or make a pull request.
Following are missing figures/examples:
- Figure 12.14: The effect of λ





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}